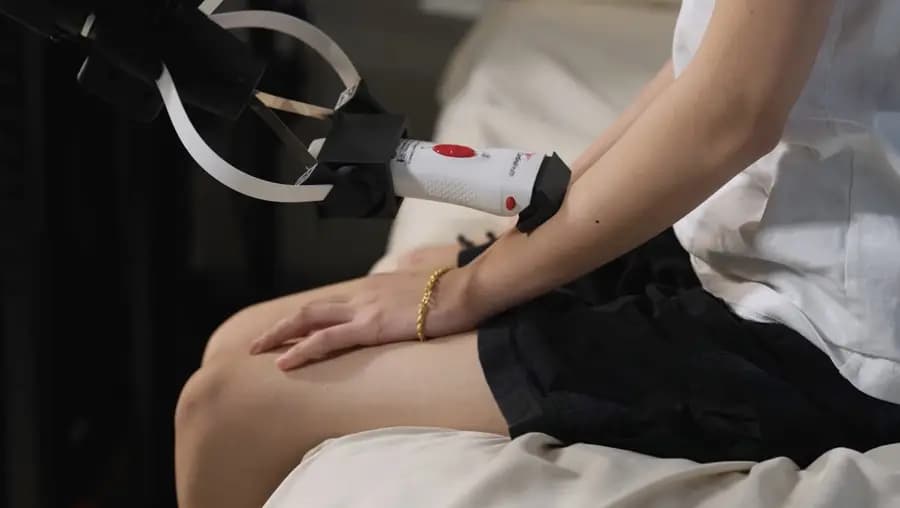
Children with speech disorders, such as a lisp, often struggle to be understood by family, teachers and friends — making school situations and everyday communication harder. And with too few speech-language pathologists nationwide to meet the demand, many kids don’t get the consistent support they need.
Key Takeaways
- Developing an AI tool aimed at helping children who struggle with speech disorders
- CMU's LTI faculty work together to develop cutting edge audio and video- based AI tools
- Studies demonstrate that children's speech improves if the AI model learns their vocal identity
Developing an AI tool aimed at helping children who struggle with speech disorders
Researchers at Carnegie Mellon University's School of Computer Science are working to fill that gap with an artificial intelligence tool designed specifically for children. Unlike most speech-reconstruction technologies — which are typically built for adults — CMU's system generates corrected audio using the child's own voice.
Developing an AI tool aimed at helping children who struggle with speech disorders
Researchers at Carnegie Mellon University's School of Computer Science are working to fill that gap with an artificial intelligence tool designed specifically for children. Unlike most speech-reconstruction technologies — which are typically built for adults — CMU's system generates corrected audio using the child's own voice.
Developing an AI tool aimed at helping children who struggle with speech disorders
Researchers at Carnegie Mellon University's School of Computer Science are working to fill that gap with an artificial intelligence tool designed specifically for children. Unlike most speech-reconstruction technologies — which are typically built for adults — CMU's system generates corrected audio using the child's own voice.
That distinction matters: The researchers said children learn speech targets more effectively when they can hear how they would sound saying the word correctly, rather than listening to an adult or neutral synthetic voice.
There’s a broad body of evidence that reflective debriefs are effective to help people apply their knowledge in a new context.
Jessica Hammer
Director
Children's Reconstructed Speech for Speech Sound Disorders (ChiReSSD) combines machine learning with human speech to generate audio clips of corrected speech that sound like the child. For example, if a child struggles with pronouncing double-r words, like "curry," the tool can generate an audio clip of that child saying the word correctly using only a clip of the child talking and text input.
"The potential clinical applications are really significant," said David Mortensen, an assistant research professor in CMU's Language Technologies Institute (LTI). "The idea that a child could hear how they would say something in their voice, except with the sound of the disordered pronunciation removed, could be transformative."
Mortensen's interest in creating technology to assist children with speech disorders started with his daughter. He said the speech language pathologist who worked at her school was so overloaded that his daughter was only seen once or twice. Mortensen knew that his daughter would have benefited from technologies that could help speech language pathologists treat children more efficiently.
Children's Reconstructed Speech for Speech Sound Disorders (ChiReSSD) combines machine learning with human speech to generate audio clips of corrected speech that sound like the child. For example, if a child struggles with pronouncing double-r words, like "curry," the tool can generate an audio clip of that child saying the word correctly using only a clip of the child talking and text input.
Mortensen's interest in creating technology to assist children with speech disorders started with his daughter. He said the speech language pathologist who worked at her school was so overloaded that his daughter was only seen once or twice. Mortensen knew that his daughter would have benefited from technologies that could help speech language pathologists treat children more efficiently.
Children's Reconstructed Speech for Speech Sound Disorders (ChiReSSD) combines machine learning with human speech to generate audio clips of corrected speech that sound like the child. For example, if a child struggles with pronouncing double-r words, like "curry," the tool can generate an audio clip of that child saying the word correctly using only a clip of the child talking and text input.
There’s a broad body of evidence that reflective debriefs are effective to help people apply their knowledge in a new context.
Jessica Hammer
Director
"The potential clinical applications are really significant," said David Mortensen, an assistant research professor in CMU's Language Technologies Institute (LTI). "The idea that a child could hear how they would say something in their voice, except with the sound of the disordered pronunciation removed, could be transformative."
Mortensen's interest in creating technology to assist children with speech disorders started with his daughter. He said the speech language pathologist who worked at her school was so overloaded that his daughter was only seen once or twice. Mortensen knew that his daughter would have benefited from technologies that could help speech language pathologists treat children more efficiently.
"The potential clinical applications are really significant," said David Mortensen, an assistant research professor in CMU's Language Technologies Institute (LTI). "The idea that a child could hear how they would say something in their voice, except with the sound of the disordered pronunciation removed, could be transformative."
Mortensen's interest in creating technology to assist children with speech disorders started with his daughter. He said the speech language pathologist who worked at her school was so overloaded that his daughter was only seen once or twice. Mortensen knew that his daughter would have benefited from technologies that could help speech language pathologists treat children more efficiently.
CMU's LTI faculty work together to develop cutting edge audio and video- based AI tools
Professor Carlos Busso and Ph.D. student Karen Rosero, both in the LTI, see ChiReSSD as a critical step to developing both audio and video tools that can address children's speech disorders. While ChiReSSD focuses on audio generation, Rosero and Busso developed video-based AI tools in previous work to analyze speech articulation after cleft lip and palate repair surgery.
"The big idea we are working toward is to generate speech that sounds like the kids and generate facial images that look like the kids," Busso said. "These audio and video clips can be combined to compare and contrast disordered and reconstructed speech. Then, we can localize the errors the children are making and create more targeted interventions, like particular words that address the specific speech issue."

Studies demonstrate that children's speech improves if the AI model learns their vocal identity
ChiReSSD only needs an audio clip of the child to generate reconstructed speech, and it can be of the child saying anything. The tool separates a child’s voice identity — their pitch or acoustic patterns — from the phonetic content of their speech, or what they're saying. The AI based model learns from speech representations of the child's vocal identity. The system then identifies and corrects the mispronunciations based on the phonetic content. Finally, using the understanding of the child's vocal identity and a text input, like the words “chicken curry” or “rabbit,” ChiReSSD generates a corrected audio clip that sounds like the child saying these target words.
"Psychological studies demonstrate that having the same voice as a reference benefits the patient," Rosero said. "For children, if the text-to-speech tool provides an adult or a standard plain voice, it may not be as beneficial as having their own voice as a reference for what to target in pronunciation."
Busso said this work makes significant strides in audio speech correction. The team's next step will be to focus on making the same impact in video.
Along with the LTI researchers, the team included Eunjung Yeo, a visiting scholar previously in SCS; Courtney Van'T Slot, a speech language pathologist; and Rami Hallac, an associate professor from the University of Texas Southwestern Medical Center.
More Stories From
A School of Computer Science Story
Carnegie Mellon’s School of Computer Science is widely recognized as one of the first and best computer science programs in the world. Visit the School of Computer Science website.